Chameleon leverages the capability of the hardware for scalable, inference-focused intermittent computing. Chameleon allows the programmer to write multiple tiers of the same application with lower computational complexity.
Overview
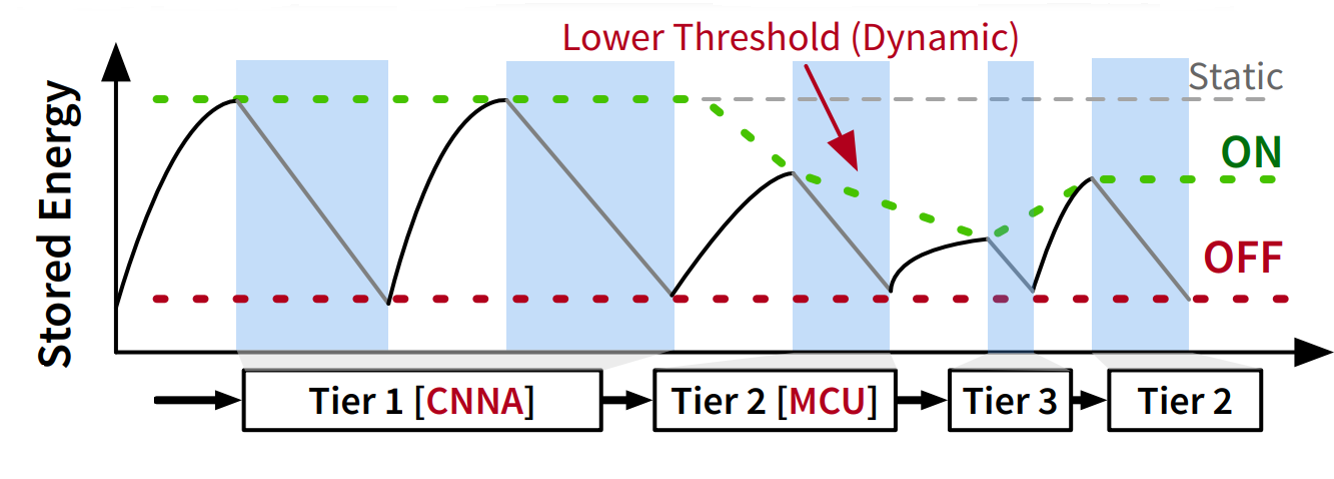
The core idea of Chameleon is to embrace scalability in hardware as well as software, providing a seamless way to degrade or upgrade tasks across diverse computational units. As the rate of energy decreases , Chameleon changes the threshold for starting computation, and switches to a lower tier, which in this case means switching the main inference task from being hosted on the CNN accelerator, to host on the MCU (in a lighter form). Basically, a tier is a set of tasks that together form a control flow graph, whereas tasks are atomic code blocks that perform sensing, computations, communication, etc. Chameleon allows the programmer to write multiple tiers of the same application with lower computational complexity—which can execute on different computational units (e.g., MCU, accelerators, or both)—that can help maintain the latency and deadlines requirements under changing energy conditions. Each tier is a complete application with potentially different approaches to solving the same inference problem (i.e., deep learning, signal processing) and is computationally independent of all other tiers. A lower tier must require less energy than a higher tier. Chameleon’s scheduler (tier selector) can automatically adapt to the best tier under given energy conditions. Threshold and tier selection is assisted by an energy prediction model which leverages energy measurements and other heuristics for estimating current and future energy availability and choosing which tier to dispatch.
